


从Token到机器劳动力:AI正在从工具变成「工人」
文章提出AI正从工具演变为可交易的‘机器劳动力’,强调商业化核心应转向对工作成果的标准化、可验证与定价,而非聚焦于token或GPU等中间计量单位;市场将经历从原始token到行业化劳动力、再到可编程结果的四阶段演进,人类角色转向复核、责任承担与最终判断。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成原文标题:A Market for Machine Labor
原文作者:律动BlockBeats
原文来源:https://x.com/__sishir/status/2059696012466217220
转载:火星财经
编者按:当 AI 开始写代码、处理客服工单、审阅法律文件,一个更底层的问题正在浮现:企业真正购买的,究竟是 token、GPU 小时,还是被完成的工作?
这篇文章提出了一个值得关注的框架:AI 的商业化不应只被理解为「算力市场」或「模型调用市场」,而是正在走向一个新的「机器劳动力市场」。在这个市场中,token 只是计量单位,GPU 是投入品,模型是生产工具,真正被定价和交易的对象,是软件直接完成的经济性劳动。
文章的核心判断在于,AI 定价机制会经历从原始 token、标准化模型能力,到行业化劳动力,再到可编程结果市场的演进。也就是说,未来企业可能不再关心某项任务由哪一个模型、哪一种 GPU 完成,而是关心它是否在规定延迟、准确率、可靠性和成本范围内,交付了符合标准的结果。
这也意味着,AI 对人类劳动市场的影响未必只是简单替代。随着机器承担更多可标准化、可验证的工作,人类的角色可能转向复核、责任承担、上下文管理与最后判断。某些场景中,最后 1% 的人类判断反而会变得更有价值,因为它可以释放大规模自动化的 99%。
从这个角度看,AI 市场的下一阶段竞争,或许不再只是模型能力之争,也不是单纯的算力价格战,而是谁能率先把「工作」标准化、可验证、可定价,并最终让机器劳动力成为一种可以被采购、结算和交易的新型生产要素。
以下为原文:
生产力浪潮过去总是来自为人类生产工具和软件,以优化工作的完成方式。电子表格帮助会计和分析师,传送带提高吞吐量,锤子放大人的杠杆。但真正的劳动始终来自人类。
现在,AI 正在端到端地产出工作成果,直接执行劳动本身。它可以写代码、处理客服工单、审阅法律文件。整个技术栈的末端正在发生压缩:旧的技术栈是支持劳动,新的技术栈则开始生产劳动。
如果你最近听过关于 AI 金融化的讨论,大概会听到 Jensen 等人说,LLM token 和/或 GPU 小时正在成为新的大宗商品。这种直觉可以理解,因为 token 可计量、可计费,也容易画成图表;GPU 小时背后也有数十亿美元资金流入。但 token 仍然只是计量表,GPU 小时只是投入品,没有人是为了拥有它们本身而购买它们。人们真正想要的是把工作完成。AI 正在把技术栈本身变成劳动力来源。

机器劳动力:由软件执行、具有经济用途,并被销售到生产环节中的工作。
市场已经在朝这个方向移动。Benchmark 的 Sarah Tavel 倾向于通过外包劳动力市场,而不是软件品类,来理解这一机会。如果某项可重复任务本来就由专门的离岸团队或专业服务公司来完成,那么它往往也是适合由 AI 交付的工作。a16z 的 Alex Rampell 将其称为「软件吞噬劳动」:软件的下一幕,是亲自完成工作。Sequoia 的 Julien Bek 则从另一个角度描述了同样的变化:服务正在变成软件,copilot 卖的是工具,而 autopilot 卖的是工作。
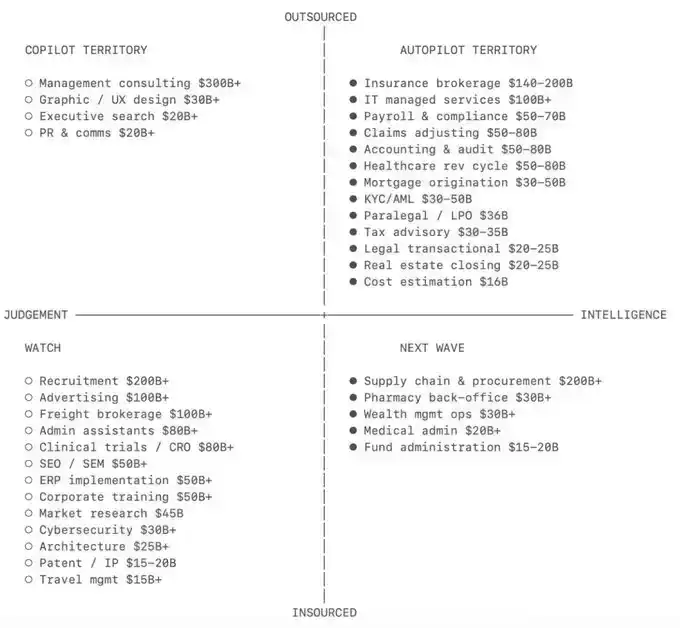
结果定价背后缺失的市场
席位定价按访问权限收费,token 定价按使用量收费。结果定价则是在工作完成时收费。结果定价让我们向前迈出了一步,但它仍然没有回答一个问题:谁来决定价格?
如果机器劳动力可以被直接购买,价格就应该来自供应商之间的竞争。这些供应商必须能够满足同一类任务或工作完成标准,而这就需要在不同行业和任务内部建立标准化。
目前的做法是使用 LLM token,但原始 token 只是最底层。每桶石油只是一个计量单位,真正交易的是某一特定等级的石油桶,具有明确的质量、交付条款和市场价格。一桶布伦特原油和一桶高硫重质原油并不是同一种商品。LLM token 也是如此。token 只是计量单位,真正重要的是其背后的智能:模型质量、基准测试下限、延迟、上下文窗口、可靠性和交付保证。来自前沿代码模型的 100 万个 token,和来自廉价通用模型的 100 万个 token,并不是同一种商品。市场需要标准化的推理等级,就像能源市场需要标准化的石油等级一样。
Anjali Shriva 直接指出了这一点:token 并不是一个固定的成本单位。它的经济性会随着上下文长度、任务结构、输入/输出比例、重试次数、工具调用和 Agent 工作流而变化。短提示词里的一个 token,和被埋在长 Agent 循环中的一个 token,并不是同一种经济对象。
我们在人类劳动力市场中早就这样做了。没有人会把放射科医生当作一种泛化的「人类小时」来雇佣。人们会看培训背景、执照认证、专业方向、从业年限、可用性、声誉、责任承担等。不同的人类合同规格,对应着不同的最低标准和等级预期。
人类劳动力市场本来就是依靠这些规格运转的,只是这些规格往往混杂、定性,并充满各种代理指标。机器劳动力会让这些规格变得更加显性,也更可量化。
对于 LLM 或 Agent 来说,技能、经验、速度和可靠性这些指标,都可以被直接写入合同:基准测试分数、延迟、吞吐量、上下文窗口、最大输出长度、工具使用准确率、正常运行时间、错误率。我们可以按照可量化的预期和结果来采购劳动力。
TheGrid.ai 的合同规格,本质上就是一个资格筛选器,再加上针对 LLM 输出的价格竞争。供应商只要满足规格,就可以进入竞争:
智能基准测试 ≥ 下限
延迟 ≤ 上限
吞吐量 ≥ 下限
正常运行时间 ≥ 下限
错误率 ≤ 上限
一旦供应商都达到了同样的最低门槛,它们就开始在价格上竞争。买方要问的是:哪一个供应商能以最优价格交付所需的劳动力?
放射科医生的招聘,在 LLM 语境下就变成了可测量的问题:哪些 LLM 能够以高熟练度读取 X 光片,并在明确的延迟、上下文窗口和其他基于结果的合同规格内完成任务。
结果,是买方衡量成功的方式;劳动,是被供应的经济活动;token,则是机器在完成工作过程中消耗的燃料。
The Grid 就是机器劳动力市场。
从 token 到机器劳动力市场
市场可以为技术栈的投入定价,但如果要为产出定价,就需要一个机器劳动力市场。买方并不关心 GPU 小时。模型端点本身也不稳定:它们会被改名、弃用、包装,或者直接退役。
用户和流动性都讨厌频繁变化。GPU 和模型会持续演进,但稳定的单位是工作本身。
我认为,市场会沿着以下路径演化。每往上一层,被购买的东西就越抽象、越有价值,但也越难验证。The Grid 应该逐步沿着这条梯子向上攀升:
原始 token → 商品化 LLM 能力市场 → 商品化劳动力市场 → 可编程结果市场
第一阶段:原始 token
Claude 4.7、GPT 5.5、Kimi 2.6、DeepSeek V4、GLM 5 等。
今天,买方从推理供应商那里购买原始模型输出。他们发送自己的提示词,接收推理结果,并按使用量付费。这很容易验证,但它仍然只是原材料。买方真正想要的不是 token,而是以最佳价格获得有用的智能。
第二阶段:商品化 LLM 能力市场
例如 text/usd、code/usd、agent/usd 等。
买方不再选择某一个具体模型,而是选择自己需要的智能类别。买方仍然掌握工作流、提示词、数据和应用逻辑。The Grid 只是把每一次请求路由到符合合同规格、且价格最低的合格模型。
注:这是高于原始 token 的第一个真正抽象层,也是 TheGrid.ai 目前所处的位置。
第三阶段:商品化劳动力市场
例如 accounting/usd、support_agent/usd、legal/usd、healthcare/usd、radiology/usd 等。
随着模型变得更加专业化,能力市场可以进一步演变为行业特定市场。这类似于人类在不同劳动力市场中的专业分工。
在这一层,我们销售的是适合特定劳动力垂直领域工作流的推理能力。随着细分行业模型越来越普遍,这类市场会迅速扩张。相关例子包括 Cursor 的 Composer、面向法律工作的 Harvey,以及面向医疗健康的 EvidenceOpen。
第四阶段:面向 Agent 的可编程 RFQ 与结果市场
例如 support_ticket_resolved/usd、pr_merged/usd、claim_processed/usd 等。
最后一层,是 The Grid 从推理市场走向机器劳动力市场的地方。
这一层需要 RFQ(询价请求)、托管账户、延迟结算、买方确认、供应商声誉、扣回机制、争议解决等机制。它很可能先从 RFQ 开始,而不是直接采用订单簿。买方定义工作内容、约束条件、验收标准和结算条款,Agent 竞标完成任务。The Grid 则帮助路由、定价、验证和结算这些工作。
这是最有价值的一层,但也是最难验证的一层,因为结果可能延迟、主观且容易被操纵。一个客服工单可能会重新打开;一个 PR 可能通过了测试,但仍然造成糟糕的架构。
总价 = 完成工作的成本 + 承担风险的成本
一个工作流不会因为智能有了市场,或者智能变得更便宜,就自动变成一个市场。有些工作高度依赖私有上下文,比如客户历史或内部政策。工作越依赖上下文,就越不可能在开放市场中被干净地清算。[@hypersoren https://hypersoren.xyz/posts/cybernetic-arbitrage/]
市场需要揭示哪些劳动力类别会扩张,哪些会收缩。
「机器劳动力 vs 人类劳动力」,还是「机器劳动力 & 人类劳动力」
Anjali Shriva 在其机制设计草稿中指出,AI 叙事太常被描述为替代。但实际上,它更像是一场协调问题:当人类和机器都参与生产时,工作、归因、激励和价值会如何被重新组织。
今天,企业内部许多 AI 使用仍然被困住了,因为员工私下使用 AI,工作流仍然锁定在个体身上,企业无法为这些生产力提升定价,也无法规模化这些收益。
大多数可自动化的工作可能都会转移给机器。一部分工作会变成人类复核、责任承担、训练和上下文管理。在某些情况下,最后 1% 的人类判断会变得更加有价值,因为它可以大规模解锁那 99% 的自动化工作。
Rachel Su Park 的《Brave New World of AI Markets》指出,AI 的 TAM 不应被简单建模为对现有人类劳动力支出的替代,因为它同时改变了价格和数量。随着工作成本降低,单位价格可能下降,但消费数量可能扩张,因为现有工作会被更频繁地消费,过去不具备经济性的全新工作也会变得可行。文章将其概括为:
P × Q:市场规模 = 单位工作价格 × 被消费的工作数量
如果 AI 让客服互动变得更便宜,公司就可以提供 24/7 全天候服务能力。这个市场不会只是旧客服劳动力市场的廉价版本,而可能变成一个规模更大的客户互动市场。
AI 是一个扩张型市场,因为当工作成本下降时,需求并不会保持不变。
劳动力层
机器劳动力市场应该从那些可以被清晰定义规格的工作开始。GPU 小时包含太多投入信息,只能告诉你是什么支撑了工作;而对完整结果定价又太复杂,过于依赖上下文。随着验证、声誉和风险/保险定价逐步由机器接管,市场才会继续走向纯结果层。
机器劳动力可以变得可交易,因为买方会越来越不关心是哪一个模型或哪一种 GPU 生产了工作,而更关心工作本身是否以正确价格达到了合同规格中的最低标准和等级。Agent 对这些底层来源甚至会更不在意。
机器现在已经可以直接执行具有经济用途的工作,而这种工作可以被定义、测量、定价、采购,并最终被交易。电力、算力、模型和 token 当然仍然重要,但它们都还处在上游。
下游才是工作真正完成的地方,而市场正在走向一个更简单的对象:机器劳动力。
为你推荐
![]()
商务合作:TG:@Lottie96
Copyright 火星财经 All Rights Reserved.